
La confidentialité des données
Vous avez probablement déjà fait ce geste. Copier un extrait de contrat, un compte rendu client, un tableau financier ou des notes d'entretien dans un outil d'IA pour aller plus vite. Sur le moment, le gain est réel. Le problème commence juste après. Où part cette donnée ? Qui peut y accéder ? Que reste-t-il dans l'historique, les journaux, les sauvegardes ou chez un sous-traitant que vous n'avez jamais vu ?
C'est là que la confidentialité des données cesse d'être une question de principe. Elle devient une question d'architecture, de méthode et de discipline opérationnelle. Pour un indépendant, un cabinet ou une PME, le vrai sujet n'est pas seulement d’“être conforme”. C'est de garder la main sur ce qui circule, ce qui se stocke et ce qui peut ressortir plus tard.
Table des matières
- Comprendre le cadre légal de la confidentialité en France
- Les nouveaux risques de l'IA pour vos données professionnelles
- Les mesures techniques pour reprendre le contrôle de vos données
- Déployer les bonnes politiques organisationnelles
- Checklists pour les secteurs sensibles santé finance juridique
- Comment une solution locale répond à ces enjeux
- Votre prochain pas vers la maîtrise de vos données
Comprendre le cadre légal de la confidentialité en France
L'incident classique arrive rarement sur la base source. Il arrive au moment où une équipe exporte un tableau, partage un graphique ou colle un extrait dans un outil d'analyse en pensant que le plus sensible a déjà été retiré. En France, ce raisonnement est trop court, parce que la confidentialité ne repose pas sur un bloc unique de règles.
Le cadre français combine en pratique deux logiques juridiques. D'un côté, le secret statistique issu de la loi de 1951. De l'autre, la protection des données personnelles issue de la loi de 1978, comme le rappelle l'Insee dans son explication du cadre français.
Deux régimes à connaître en même temps
Dans les projets IA que l'on voit en entreprise, l'analyse juridique est souvent réduite au RGPD. Cela ne suffit pas dès qu'un traitement porte sur des données qui identifient directement une personne, ou qui permettent de la retrouver par recoupement à partir d'un résultat apparemment neutre.
Le point utile chez l'Insee est très concret. Un tableau, un indicateur ou un graphique peut rester protégé s'il permet une réidentification. La conséquence opérationnelle est simple. La confidentialité ne se gère pas seulement à l'entrée du workflow. Elle se gère aussi en sortie.
Règle pratique
Si un graphique, un tableau filtré ou un export permet de remonter à une personne ou à une entité identifiable, le risque reste présent, même si le document paraît agrégé.
Autre repère important pour les équipes métiers. En France, la logique de confidentialité s'apprécie aussi dans le temps long. Certaines données ne deviennent librement diffusables qu'après des délais très étendus selon leur nature et le régime applicable. Pour un responsable de traitement, cela change le réflexe de départ. Il faut raisonner en durée de conservation, en accès autorisés et en conditions de réutilisation, pas seulement en anonymisation rapide avant envoi.
Ce que cela change dans vos usages quotidiens
Pour un cabinet, un consultant ou une PME, le bon cadre de lecture tient en trois questions :
- Quelle est la nature réelle de la donnée ? Donnée personnelle, donnée métier confidentielle, donnée sensible, donnée statistique, ou combinaison de plusieurs catégories.
- À quel stade se trouve-t-elle ? Source brute, extrait, résumé, tableau, graphique, note d'analyse.
- Le recoupement reste-t-il possible ? Une donnée transformée n'est pas automatiquement une donnée sûre.
C'est là que les erreurs de mise en œuvre apparaissent. Une équipe retire les noms d'un fichier client avant de le soumettre à une IA. Le geste va dans le bon sens. Mais si le fichier conserve une fonction rare, une localisation précise, des dates d'événements ou des informations contractuelles distinctives, l'identification reste possible pour un destinataire bien informé.
Voici une grille simple pour arbitrer sans se raconter d'histoire :
| Situation | Réflexe insuffisant | Réflexe utile |
|---|---|---|
| Export de tableau client | Supprimer les noms | Vérifier aussi les colonnes contextuelles et le risque de recoupement |
| Graphique de performance | Considérer qu'un graphique est forcément anonyme | Tester s'il révèle un individu, un dossier ou une entreprise identifiable |
| Rapport synthétique | Protéger uniquement la base source | Contrôler aussi la sortie, la diffusion, la durée de conservation et les destinataires |
En pratique, une politique de confidentialité sérieuse pour l'IA doit donc couvrir la collecte, la transformation, la sortie et la circulation de l'information.
C'est ce passage de la règle au geste quotidien qui fait la différence entre une conformité déclarative et un dispositif réellement maîtrisé.
Les nouveaux risques de l'IA pour vos données professionnelles
Le risque nouveau apporté par l'IA générative n'est pas seulement technique. Il tient au fait que vous confiez un morceau de votre activité à une chaîne d'acteurs que vous ne voyez pas. Interface, fournisseur du modèle, hébergement, journaux, prestataires techniques, parfois sous-traitants supplémentaires. Le problème n'est plus juste “est-ce chiffré ?”. La vraie question devient “qui traite quoi, pour quelle finalité, et sous quelles instructions ?”.
Pour visualiser ce parcours, gardez ce schéma en tête :
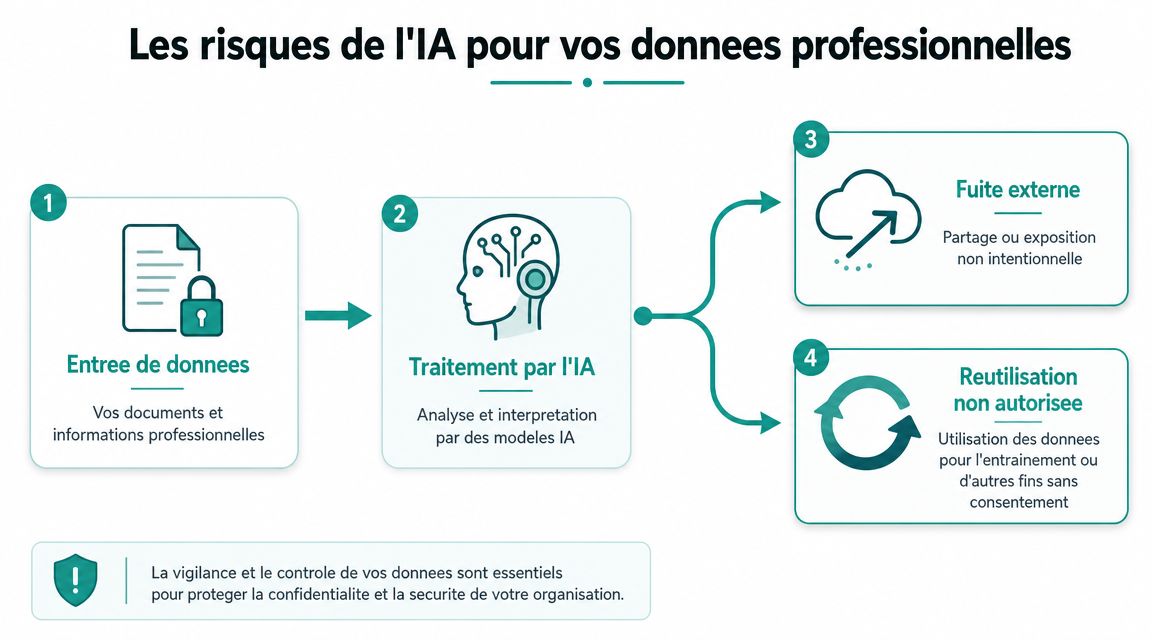
Le vrai problème n'est pas l'outil mais la chaîne
Le cadre rappelé par le service public pour les relations entre responsable de traitement et sous-traitant est très clair. Le RGPD impose d’encadrer contractuellement les traitements, de formaliser les instructions et d’assurer la confidentialité. La conformité ne dépend donc pas uniquement du chiffrement. Elle dépend de toute la chaîne de sous-traitance, des finalités et de votre capacité à prouver les mesures prises.
Cela change la manière d'évaluer un outil d'IA. Une belle interface ne dit rien sur les engagements réels. Un fournisseur peut proposer des fonctions utiles tout en laissant des zones floues sur la conservation, la journalisation ou les usages secondaires.
Quand vous collez un document sensible dans une IA en ligne, vous ne faites pas seulement un envoi technique. Vous déclenchez un traitement qui doit avoir une base claire, des finalités maîtrisées et des garanties vérifiables.
Ce qui se passe quand vous collez un document dans une IA
Prenons un cas banal. Vous chargez un extrait de pacte d'associés pour demander un résumé des clauses à risque. Le flux réel ressemble souvent à ceci :
- Vous transmettez une donnée métier sensible.
- L'outil l'envoie vers un service tiers.
- Ce service peut s'appuyer sur d'autres prestataires pour exécuter, stocker ou journaliser le traitement.
- Des traces subsistent selon la politique de conservation, d'historique ou de supervision.
- Votre capacité de contrôle dépend du contrat, pas de l'ergonomie.
Le point aveugle le plus fréquent est là. Beaucoup de professionnels pensent encore en termes d'écran. Ils voient “mon chat IA”. Juridiquement et opérationnellement, ils devraient voir une chaîne de sous-traitance.
Une bonne mise à niveau consiste à poser ces questions avant tout usage :
- Qui reçoit les données ? Le fournisseur affiché, ou aussi d'autres prestataires ?
- Quelles finalités sont prévues ? Réponse immédiate, journalisation, amélioration du service, support, conservation.
- Quelles instructions pouvez-vous imposer ? Ce point sépare l'outil grand public du cadre professionnel.
- Pouvez-vous démontrer vos choix ? Sans traces internes, la réponse est souvent non.
La vidéo ci-dessous montre bien pourquoi l'IA n'est pas un simple logiciel de plus, mais un nouveau point de circulation des informations.
Ce qui fonctionne, dans la pratique, c'est une approche par niveau de sensibilité. Les données publiques ou marketing génériques peuvent tolérer des outils plus ouverts. Les données clients, RH, juridiques ou financières exigent un périmètre beaucoup plus strict. Ce qui ne fonctionne pas, c'est la règle implicite du type “on fait attention”. Sans critères d'usage, l'outil le plus rapide finit toujours par absorber des données qu'il n'aurait jamais dû voir.
Les mesures techniques pour reprendre le contrôle de vos données
La meilleure manière de protéger une donnée sensible n'est pas de la “sécuriser davantage” après coup. C'est d'abord de réduire ce qui circule. Ensuite seulement, vous appliquez les bons mécanismes techniques.
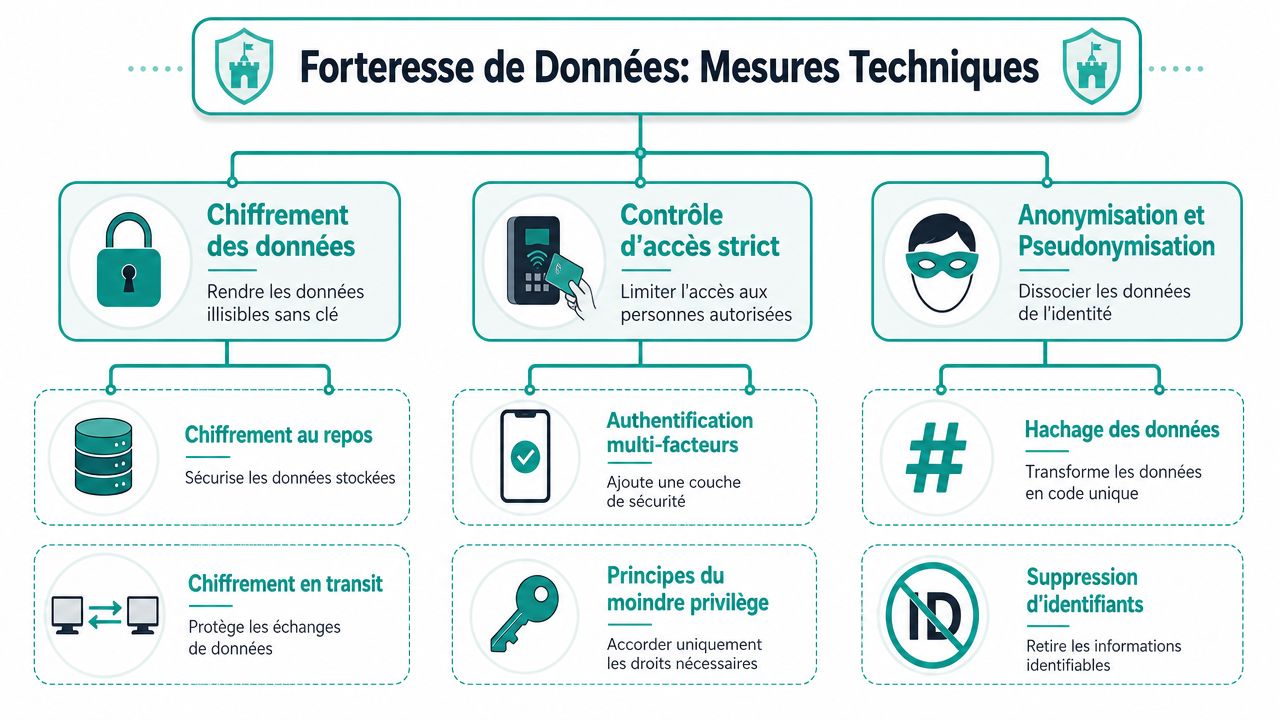
Réduire avant de protéger
Le RGPD impose de limiter la collecte au strict nécessaire et de mettre en place des mesures comme la pseudonymisation et le chiffrement. Il faut aussi garder en tête que l'anonymisation irréversible est difficile à atteindre, tandis que la pseudonymisation reste une option réversible plus pragmatique pour beaucoup d'organisations, comme le rappelle ce rappel pédagogique sur minimisation, pseudonymisation et chiffrement.
Concrètement, avant tout envoi à une IA, retirez ce qui ne sert pas à la tâche. C'est souvent plus efficace qu'une couche technique ajoutée trop tard.
Exemple simple :
- Mauvais réflexe : envoyer un compte rendu complet avec noms, e-mails, dates précises et historique.
- Bon réflexe : envoyer une version réduite avec rôles, enjeux, séquence des faits et identifiants internes temporaires.
Conseil terrain
La minimisation n'appauvrit pas forcément l'analyse. Dans beaucoup de cas, elle améliore même la qualité du prompt parce qu'elle retire le bruit.
Trois choix techniques qui changent vraiment le niveau de contrôle
Le premier pilier est le chiffrement. Il faut distinguer le chiffrement au repos et le chiffrement en transit. Le premier protège les données stockées. Le second protège les échanges entre votre poste et le service utilisé. Ce n'est pas une garantie totale de confidentialité, mais c'est une base.
Le second pilier est le stockage local. Quand vos conversations, vos documents de travail et vos historiques restent sur votre machine, vous réduisez fortement la circulation non maîtrisée. C'est la logique défendue dans les approches d’IA embarquée sur le poste de travail. Ce choix n'élimine pas tous les risques, mais il retire un intermédiaire important.
Le troisième pilier est la gestion des accès. Une clé API personnelle, utilisée dans un cadre maîtrisé, clarifie qui appelle quel modèle. Vous séparez l'outil d'interface du fournisseur de modèle. C'est souvent plus propre qu'un abonnement opaque où tout transite dans un environnement que vous ne contrôlez pas vraiment.
Voici un repère opérationnel :
| Pilier | Ce qu'il apporte | Ce qu'il ne règle pas seul |
|---|---|---|
| Chiffrement | Protège stockage et échanges | N'efface ni la surcollecte ni une mauvaise gouvernance |
| Stockage local | Réduit la diffusion des données et l'exposition côté tiers | Ne remplace pas les règles internes |
| Clés API propres | Clarifie les accès et les responsabilités | N'empêche pas un mauvais prompt ou un envoi inadapté |
Anonymisation et pseudonymisation ne servent pas au même usage
C'est un point qui crée beaucoup de confusion.
Anonymiser, c'est retirer de façon irréversible la possibilité d'identifier une personne. En théorie, c'est idéal. En pratique, c'est difficile, surtout quand plusieurs éléments peuvent être recoupés.
Pseudonymiser, c'est remplacer l'identité par un identifiant ou une référence réversible sous contrôle. Cela permet encore de travailler utilement.
Prenons trois cas :
Cabinet marketing
Vous analysez des verbatims clients. Remplacer les noms par “Client A”, “Client B” et retirer les coordonnées garde la matière utile pour l'analyse.Consultant RH
Vous demandez à une IA de synthétiser des retours d'entretien. Garder l'intitulé du poste mais supprimer nom, e-mail et éléments biographiques réduit déjà fortement le risque.Cabinet conseil
Vous faites relire une note de cadrage. Remplacez le nom du client, les montants exacts et les références internes par des marqueurs temporaires.
Ce qui ne marche pas, c'est la fausse anonymisation. Retirer le nom tout en laissant le poste exact, la ville, la chronologie et le secteur suffit parfois à retrouver la personne.
Déployer les bonnes politiques organisationnelles
Une entreprise peut disposer d'un stockage local, de clés API séparées et d'un chiffrement propre, puis perdre tout bénéfice parce qu'un collaborateur colle un document complet dans un service public. La technologie réduit le risque. Elle ne crée pas le réflexe.

Une charte d'usage simple vaut mieux qu'une règle floue
La CNIL rappelle une logique de minimisation et une obligation de notification des violations de données dans les 72 heures lorsqu'un risque existe pour les personnes, comme le résume ce rappel des obligations de minimisation, détection et notification. Cette contrainte a une conséquence directe. Sans journalisation ni détection d'incident, vous ne savez ni ce qui a été exposé, ni quand, ni par qui.
La bonne politique interne tient souvent sur une page. Elle répond à cinq questions :
Quelles données sont interdites dans une IA publique
Contrats non signés, données clients identifiantes, dossiers RH, éléments de santé, secrets d'affaires.Quelles données sont autorisées sous conditions
Notes pseudonymisées, brouillons sans identifiants, documentation interne non sensible, textes déjà publics.Quels outils sont validés
Interface locale, fournisseur contractuellement encadré, environnement séparé pour les tests.Qui peut utiliser quoi
Tout le monde n'a pas besoin du même niveau d'accès ni des mêmes fonctions.Que faire en cas de doute
Une règle simple. Si vous hésitez, vous retirez les identifiants ou vous ne l'envoyez pas.
Préparer l'incident avant qu'il n'arrive
La plupart des structures n'ont pas besoin d'un programme de gouvernance lourd pour progresser. Elles ont besoin d'un protocole praticable.
Un cadre utile ressemble à ceci :
Journaliser les usages sensibles
Qui a envoyé quoi, dans quel outil, pour quelle tâche.Définir un canal d'alerte interne
Une adresse ou un référent. Pas une boîte oubliée.Préparer une procédure de triage
Identifier rapidement la nature de la donnée, l'outil concerné, le niveau d'exposition probable.Conserver les preuves utiles
Capture, historique, type de document, action corrective engagée.
Une politique efficace ne cherche pas à empêcher toute erreur humaine. Elle cherche à rendre l'erreur visible tôt, compréhensible vite, et traitable sans improvisation.
Ce qui fonctionne bien en PME, c'est un rituel court. Revue mensuelle des outils IA utilisés, rappel des catégories interdites, mise à jour des accès, vérification de quelques cas réels. Ce qui fonctionne mal, c'est le document juridique de plusieurs pages que personne ne relit après signature.
Checklists pour les secteurs sensibles santé finance juridique
L'incident typique ne ressemble pas à une fuite massive. Il commence par une demande banale. Un professionnel copie un extrait dans un outil IA pour gagner dix minutes. Le texte semble neutre. En réalité, il suffit de quelques détails pour réidentifier un patient, déduire une stratégie d'investissement ou exposer une ligne de défense.
Dans ces trois secteurs, la bonne méthode consiste à raisonner par tâche, puis par niveau d'exposition. La question utile n'est pas seulement "la donnée est-elle personnelle ?". C'est aussi "que permet-elle de reconstruire si elle sort du bon périmètre ?".
Santé
En santé, le seuil d'exigence est plus haut parce que le contexte compte autant que l'identité. Un prénom supprimé ne rend pas un compte rendu inoffensif si le service, la pathologie rare, la date et le parcours de soins restent visibles. En pratique, les données de patients identifiants ou facilement réidentifiables demandent un cadre d'hébergement et d'accès adapté. Ce point se vérifie avant le test, pas après.
Une checklist utile :
À faire
- Limiter l'usage de l'IA à une finalité précise. Structurer un texte, normaliser une terminologie, préparer une trame de questions, sans injecter de dossier complet.
- Pseudonymiser réellement. Retirer les identifiants directs, mais aussi les combinaisons d'indices qui permettent de reconnaître une personne.
- Travailler sur des extraits minimaux. Un paragraphe suffit souvent pour une reformulation ou une classification.
- Séparer les usages documentaires des usages cliniques. Un outil peut aider à traiter la forme d'un document sans intervenir sur la décision de soin.
- Tester les flux techniques sur des documents de démonstration. Par exemple, pour des traitements de lecture ou d'extraction, un workflow d’OCR avec IA sur documents professionnels doit d'abord être validé sur des jeux de données neutres.
À éviter
- Envoyer un dossier patient complet dans un service IA ouvert.
- Croire qu'un résumé protège automatiquement. Un résumé de séjour, d'examen ou d'échange médical peut rester très identifiant.
- Mélanger données réelles et expérimentation dans le même environnement.
Finance
En finance, la sensibilité porte autant sur le secret d'affaires que sur les données personnelles. Une note sans nom de client peut déjà exposer une opération, une allocation, une faiblesse de contrôle ou un calendrier de marché. J'ai souvent vu le même réflexe. On retire l'identité, puis on envoie le reste. C'est rarement suffisant.
La checklist opérationnelle ressemble à ceci :
- Supprimer les montants, dates et références d'opération si la tâche ne dépend pas de ce niveau de détail.
- Isoler la méthode de raisonnement. Demander un cadre d'analyse, un plan de note ou une grille de risques plutôt qu'un avis sur le dossier brut.
- Traiter à part les documents de conformité, d'audit et de contentieux. Leur valeur tient souvent aux éléments intermédiaires, pas seulement au livrable final.
- Vérifier le risque d'inférence. Un portefeuille, une place de marché, une échéance et un secteur peuvent suffire à reconnaître le client ou l'opération.
- Conserver une trace des usages IA sur les documents sensibles quand ils alimentent une décision interne ou réglementée.
Le piège classique est le document "presque anonymisé". Il ne donne pas de nom, mais il donne assez de contexte pour reconstituer le reste.
Juridique
Dans le juridique, la confidentialité ne se limite pas aux données d'identité. La stratégie, les hypothèses, les versions de travail et les échanges préparatoires ont souvent plus de valeur que les pièces finales. C'est pour cela que les usages efficaces de l'IA restent étroits et très cadrés.
Deux règles tiennent bien dans le temps.
- Découper le travail confié à l'IA. Reformulation, extraction de thèmes, proposition de plan, harmonisation de style, vérification de cohérence formelle.
- Créer une version neutre avant traitement. Initiales ou rôles à la place des parties, chronologie simplifiée, dates relatives, faits résumés, références de pièces sans contenu intégral.
Ajoutez trois interdictions simples :
- Ne pas charger un échange avocat-client complet pour gagner du temps.
- Ne pas transmettre des projets de conclusions ou de négociation avec tous les identifiants visibles si une abstraction suffit.
- Ne pas laisser chaque collaborateur définir sa propre règle sous pression.
La bonne discipline, dans ces secteurs, consiste à demander de moins en moins de données à l'outil. Plus la consigne est précise, plus il devient possible d'obtenir une aide utile sans exposer le cœur du dossier.
Comment une solution locale répond à ces enjeux
Quand on met bout à bout les contraintes vues plus haut, une conclusion revient souvent. Plus vous rapprochez l'outil de votre poste de travail, plus vous raccourcissez la chaîne de circulation des données.
Ce que change une architecture locale
Une application desktop locale réduit un point de friction central. Vos conversations, vos documents de travail et vos historiques ne passent pas par un serveur applicatif intermédiaire. C'est particulièrement cohérent pour des usages comme la lecture de documents, l'extraction d'informations, ou les flux mêlant OCR et IA, comme on le voit dans ce cas d'usage autour de l'OCR avec IA.
Dans cette logique, IATOLL fait partie des options qui répondent à une exigence précise. Une application locale pour Mac, Windows et Linux, avec stockage sur la machine et connexion directe aux fournisseurs via vos propres clés. Pour un professionnel, cela change surtout trois choses :
- Moins d'intermédiaires entre vos documents et le modèle appelé.
- Plus de lisibilité sur les accès parce que vous utilisez vos clés API.
- Une séparation plus nette entre l'interface de travail et le fournisseur du modèle.
Pourquoi le modèle BYOK remet les accès à leur place
Le modèle BYOK (“Bring Your Own Key”) est utile quand vous voulez éviter un abonnement de plus qui absorbe vos données et vos usages dans une couche opaque. Vous choisissez le fournisseur, vous gérez la clé, vous contrôlez les accès côté compte, et vous gardez un outillage stable même si vous changez de modèle.
Ce n'est pas une solution magique. Si vous envoyez un mauvais document, l'architecture ne corrige pas l'erreur métier. En revanche, elle retire une partie du flou qui complique la confidentialité des données dans les outils en ligne classiques.
Pour beaucoup de structures, le bon compromis tient là. Une interface locale, des règles de minimisation, des documents pseudonymisés, et un choix explicite des modèles appelés. Ce n'est pas spectaculaire. C'est simplement plus gouvernable.
Votre prochain pas vers la maîtrise de vos données
Prenez le dernier document sensible que vous avez utilisé avec une IA. Pas un cas théorique. Le dernier vrai document. Ouvrez-le et faites un audit rapide en trois questions : où la donnée a-t-elle été stockée, qui a pu y accéder, et quelles garanties concrètes encadraient ce traitement ?
Si vous ne pouvez pas répondre clairement à ces trois points en moins de quelques minutes, votre pratique actuelle est trop floue. Commencez par là. Réduisez un seul workflow, pseudonymisez un seul type de document, validez un seul outil autorisé. La maîtrise revient par petits choix nets, pas par une grande politique abstraite.
Si vous voulez un cadre plus contrôlable pour vos usages quotidiens, IATOLL mérite un test. L'application réunit plusieurs modèles dans une interface locale, fonctionne avec vos propres clés API et garde vos conversations et documents sur votre machine. Pour un indépendant, un cabinet ou une PME, c'est une manière concrète de rendre la confidentialité compatible avec un usage intensif de l'IA.



